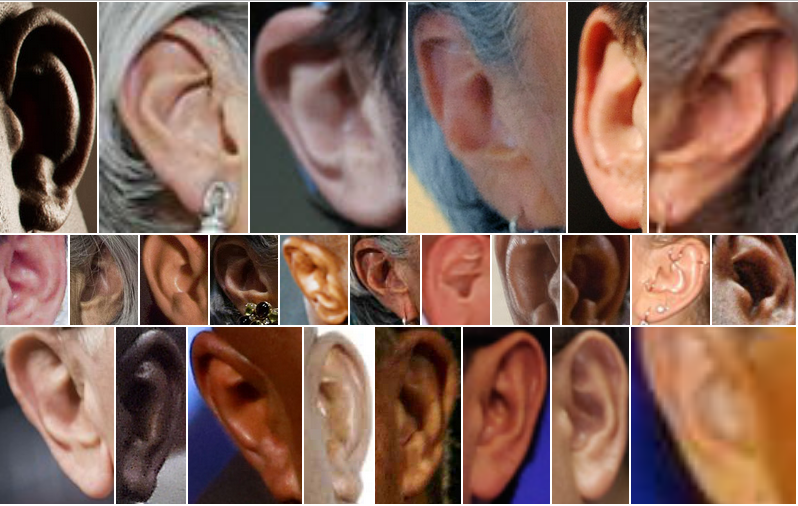
Ear Recognition Research
University of Ljubljana
Joint work of two laboratories:
- Computer Vision Laboratory, Faculty of Computer and Information Science
- Laboratory for Machine Intelligence, Faculty of Electrical Engineering