Unconstrained Ear Recognition Challenge 2019
Welcome to the Unconstrained Ear Recognition Challenge 2019!
The 2nd Unconstrained Ear Recognition Challenge (UERC) was organized in the scope of the IAPR International Conference on Biometrics 2019. The goal of the challenge was to further advance the state-of- technology in the field of automatic ear recognition, to provide participants with a challenging research problem and introduce a benchmark dataset and protocol for assessing the latest techniques, models, and algorithms related to automatic ear recognition.
The results of UERC 2019 were published in the ICB conference paper authored jointly by all participants of the challenge.
Motivation
Ear recognition is an active area of research within the biometric community. While work in this field has long focused on constrained, laboratory like-setting, recent approaches are looking increasingly at data acquired in unconstrained conditions and many techniques and approaches have been presented recently focusing on data captured in these so called “in-the-wild” settings. To promote research in these “in-the-wild” settings the Unconstrained Ear Recognition Challenge (UERC) 2019 will bring together researchers working in the field of ear recognition and benchmark existing algorithms on a common dataset and under a predefined experimental protocol. UERC 2019 will build on the previous challenge, UERC 2017 (available on IEEE Xplore and on arXiv.org), organized in the scope of the 2017 International Joint Conference on Biometrics (IJCB) and use the same dataset and protocol, thus enabling to examine and directly compare the progress made in the field since 2017.
The Dataset, Protocol and Performance Metrics
The challenge was held on an extended version of the Annotated Web Ears (AWE) dataset, containing a total of 9,500 ear images - see the UERC 2017 summary paper for details (available on IEEE Xplore and on arXiv.org). The images were collected with a semi-automatic procedure involving web-crawlers and a subsequent manual inspection. Because the AWE images were not gathered in controlled laboratory-like conditions, they better represent the variability in ear appearance than existing datasets of ear images. However, the problem of automatic ear recognition is also significantly harder. A few example images from the extended AWE dataset are shown below.

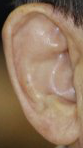
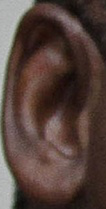

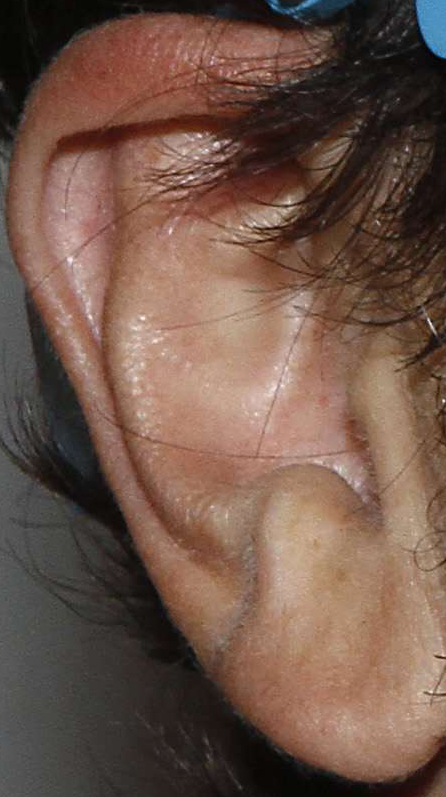
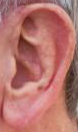
A more in depth description of the images, acquisition procedure, dataset characteristics and other information on the AWE dataset is available in the Neurocomputing paper.
UERC 2019 used three image datasets:
- part A: the main datasets of 3,300 ear images belonging to 330 distinct identities (with 10 images per subject) that was used for the recognition experiments (training and testing),
- part B: a set of 804 ear images of 16 subjects (with a variable number of images per subject) that was used for the recognition experiments (training),
- part C: an additional set of 7,700 ear images of around 3,360 identities that was used to test the scalability of the submitted algorithms.
The 3,300 images of the main dataset contain various annotations, such as the level of occlusion, rotation (yaw, roll and pitch angles), presence of accessories, gender and side. This information is also made available during training and can be exploited to build specialized recognition techniques.
The 3,300 images of the main part of the dataset was split into a training set of 1,500 images (belonging to 150 subjects) and a test set of 1,800 images (belonging to 180 subjects). The identities in the training and test set were disjoint. The purpose of the training set is to train recognition models and set any open hyper-parameters, while the test set is reserved for the final evaluation. The test set MUST NOT have been used to learn or fine-tune any parameters of the recognition model. The organizers reserved the right to exclude a team from the competition (and consequently the jointly authored ICB conference paper) if the final result analysis suggested that the test images were also used for training.
The train and test sets were split:
- Train (2,304 images of 166 subjects): 1,500 images (150 subjects) from part A and all images from part C (804 - 16 subjects).
- Test (9,500 images of 3,540 subjects): 1,800 images (180 subjects) from part A and all impostor images (7,700 - 3,360 subjects).
UERC tested the recognition performance of all submitted algorithms through identification experiments. The participants had to generate a similarity score matrix with comparisons of each image in the probe.txt file to each image in the gallery.txt file and return the resulting similarity matrix to the organizers for scoring. Thus, each participant was required to generate a 7442x9500 matrix for each submitted system.
The number of approaches that each participant was allowed to submit was not limited. However, only approaches with a least a short description (written by the participants) and some sort of original contribution, were included in the ICB summary paper of UERC 2019.
The submitted similarity matrices were scored by the organizers. Rank-1 recognition rates, complete CMC curves and the Area-under- the CMC (AUC) curve was be computed and reported for each submitted algorithm.
Starter Kit
We provided all participants with a Matlab starter kit that generated a matrix of comparisons for each sample in the dataset and computed all relevant performance metrics. The starter kit helped participants to quickly start with the research work and generate score matrices compliant with our scoring procedures. For the baseline approaches we made a number of descriptor-based approaches (using SIFTs, POEMs, LBPs, etc.) available to the participants as well as a deep learning approach, based on VGG.
All scripts that were used to generate results for the UERC 2017 summary paper were also be included in the starter kit.
Organizers
- Žiga Emeršič, PhD candidate
University of Ljubljana, Faculty of Computer and Information Science, Slovenia, EU - Assoc. Prof. Hazım Kemal Ekenel
Istanbul Technical University, Department of Computer Engineering, Turkey & École Polytechnique Fédérale de Lausanne, Switzerland - Assoc. Prof. Li Yuan
University of Science & Technology Beijing, China - Assoc. Prof. Vitomir Štruc
University of Ljubljana, Faculty of Electrical Engineering, Slovenia, EU - Assoc. Prof. Peter Peer
University of Ljubljana, Faculty of Computer and Information Science, Slovenia, EU
If you have any questions, suggestions or would like to participate in the future competitions, feel free to contact ziga.emersic@fri.uni-lj.si.